sfc软件包中文说明
sfc软件包于2016年8月25日正式出现在CRAN上,其主要功能是进行大规模物质流核算和不确定性分析。与传统物质流核算方法不同的是,sfc软件包是基于数据和模型分离的思想构建的。这种方法的优势在于能够把模型从复杂的数据结构中抽离出来,从而使研究者能够把注意力集中在模型的构建上,以避免复杂数据结构对建模过程的干扰。
1 安装sfc
sfc软件包依赖于dplyr、tidyr、triangle、zoo、sna等R软件包,因此在R平台上安装sfc之前,最好先安装好这些依赖的软件包。sfc软件包可以用如下方式安装:
install.packages("sfc")如果要安装sfc软件包的最新开发版,则可以通过以下方式:
install.packages("devtools")
devtools::install_github("ctfysh/sfc")2 数据文件
物质流核算涉及的数据的类型多且量大,同时数据存在着一定的不确定性,所以需要有一种既简单直观又易于被模型所有调用的数据格式,来管理这些数据。表1就是sfc软件包为了物质流核算所设计的一种数据文件格式,以.csv的形式存储,或者直接以数据框(data frame)的形式存在于内存中,供sfc软件包中的sfc函数调用。
与Lorenz曲线相关的指标
在前面一篇博客“对加权Gini系数的理解”中,我们已经对Lorenz曲线的构造方法进行了探讨,当时的主要目的是计算加权Gini系数。事实上,Gini系数并不能表现出Lorenz曲线的全部信息,因为同一个Gini系数可能对应不同的Lorenz曲线。为了进一步挖掘Lorenz曲线的信息,Damgaard等人1提出了Lorenz不对称系数,用来说明不公平性到底是由于低收入的人群占比太高导致的,还是由于少量人群占据了大量的收入所致。另外,学者还提出了Hoover指数(或者称为Ricci-Schutz系数以及Robin Hood指数),用来分析到底有多大比例的收入需要再分配才能实现“绝对公平”。由于Hoover指数相对比较简单,这里先探讨Hoover指数,然后再对Lorenz不对称系数进行说明。
1 Hoover指数
Hoover指数的想法是十分简单的,假设有\(n\)个人的收入分别为\(x_1,x_2,\cdots,x_n\),其平均数为\(\bar{x}\),考虑到最公平的分配方式是这\(n\)个人的收入都是\(\bar{x}\),那么每个人的缺口就是\(\|x_i-\bar{x}\|\)。这时我们可以计算出总的缺口占总收入的比例:
\[\text{HI}=\dfrac{\sum_{i=1}^n\|x_i-\bar{x}\|}{2\sum_{i=1}^n{x_i}}\]
这个比例就是Hoover指数。在Hoover指数的计算公式中需要除以\(2\),其原因是\(x_i-\bar{x}<0\)的\(\|x_i-\bar{x}\|\)的总和与\(x_i-\bar{x}>0\)的\(\|x_i-\bar{x}\|\)的总和相等,也就是说高于平均收入的人群需要拿出的收入的总和等于低于平均收入的人群需要获得的收入的总和时才能实现“绝对公平”。按照这种方式,我们很容易就能计算出“对加权Gini系数的理解”中第一个表格中数据的Hoover指数,其结果为 \(0.206\)。
对加权Gini系数的理解
1 Gini系数
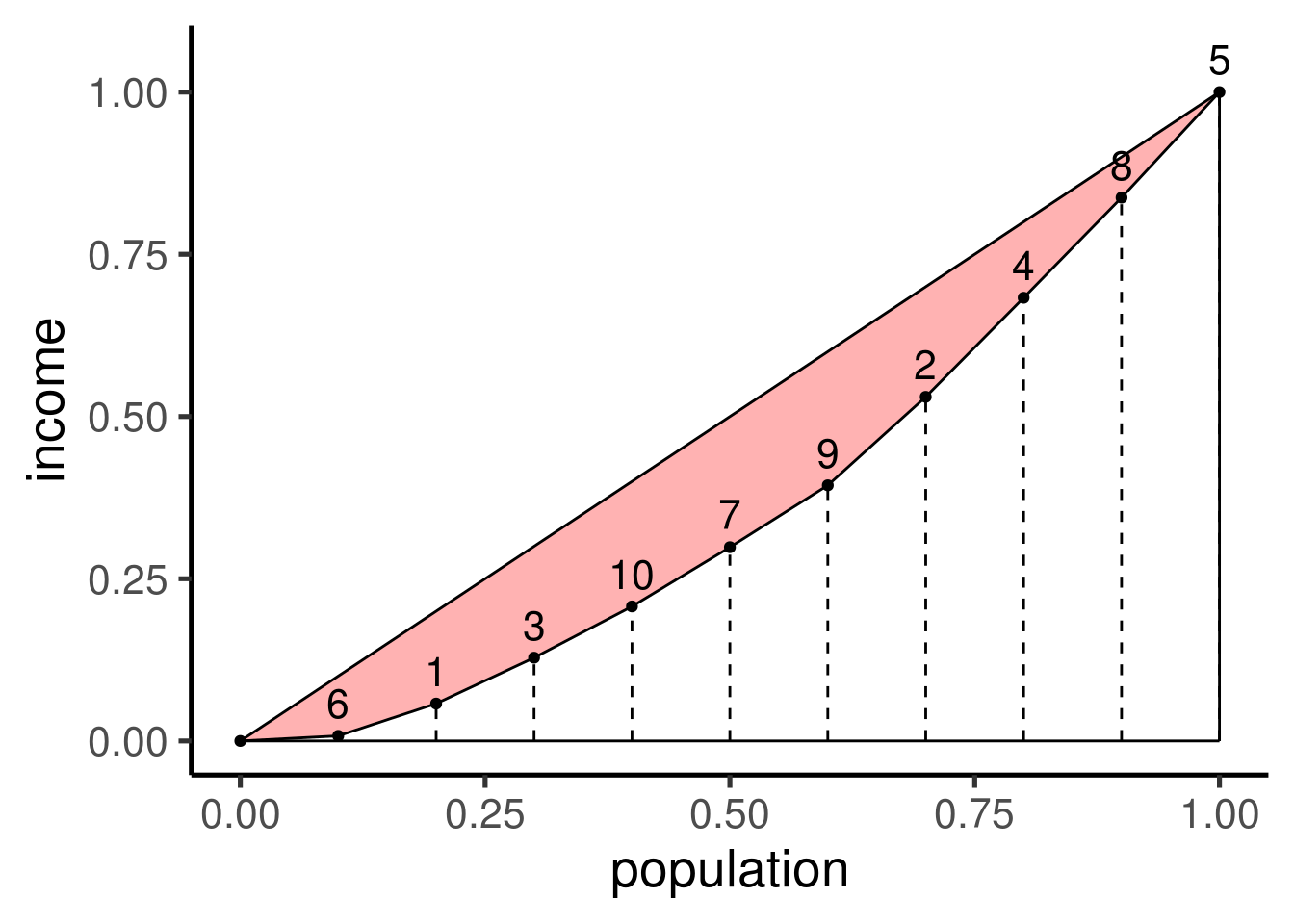
Gini系数是研究不公平性(或者说公平性)的一个重要指标。它的计算可以通过Lorenz曲线来实现。假如我们研究一个群体内部收入分配的公平性问题,那么首先可以刻画这个群体内部收入分配的Lorenz曲线,具体方式如下:假设这个群体内部共有\(n\)个人,每个人的收入分别为\(x_1,x_2,\cdots,x_n\),然后我们可以对这\(n\)个人的收入按照从小到大的顺序进行排序,得到\(x_1^\prime,x_2^\prime,\cdots,x_n^\prime\),这时我们可以构造一组坐标\((h/n,L_h/L_n)\),这里\(h=0,1,\cdots,n\),\(L_0=0\),\(L_h=\sum_{i=0}^hx_i^\prime\)。我们将这些坐标点绘制在平面直角坐标系中并依次相连,所得到的曲线就是Lorenz曲线。为了说明这一过程,假设\(n=10\),具体的收入状况如下表所示:
| id | income |
|---|---|
| 1 | 28.76 |
| 2 | 78.83 |
| 3 | 40.90 |
| 4 | 88.30 |
| 5 | 94.05 |
| 6 | 4.56 |
| 7 | 52.81 |
| 8 | 89.24 |
| 9 | 55.14 |
| 10 | 45.66 |
绘制的Lorenz曲线如下: